Table of Contents
A Practical SRE Model That CEOs Trust
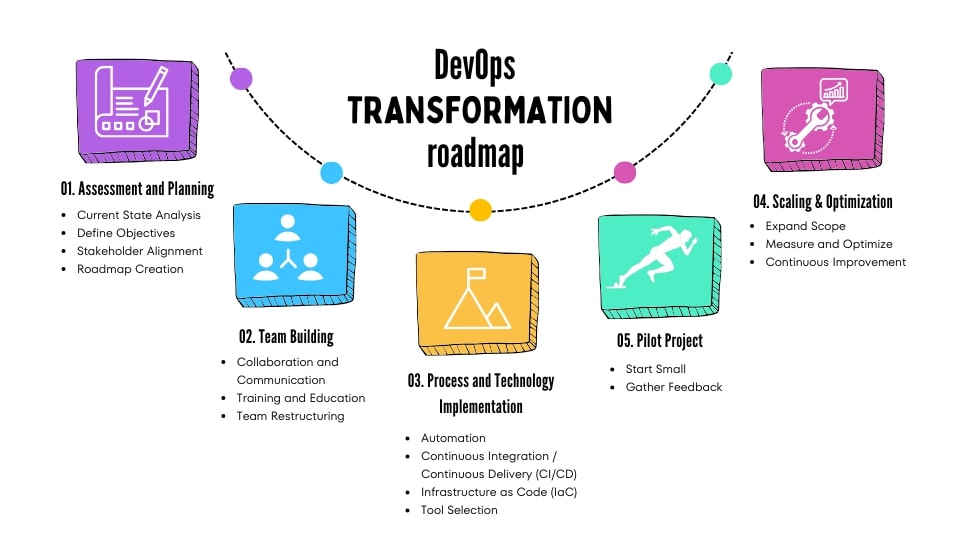
Startups often think hiring a full SRE team is the only route to reliability. In reality, a pragmatic mix of automation, runbooks, and targeted managed services delivers enterprise-grade reliability without the full headcount. Sahi helps leadership design an SRE model that protects customer experience and keeps engineering focused on product velocity.
Monitoring & Observability: Signal Over Noise
Instrument with intent: prioritize SLIs that directly reflect customer experience and business KPIs. Use centralized dashboards and anomaly detection, but enforce alert hygiene so teams respond to signal—not noise.
Runbooks, Automation & Playbooks
Concise runbooks for top incidents plus automated remediation reduce mean time to resolution dramatically. We automate common remediations (auto-scaling, restart jobs, ephemeral rollbacks) and integrate playbooks into incident channels and CI for repeatable execution.
On-Call Strategy — Scalable, Cost-Effective
Combine lightweight internal rotations with a managed incident response layer for overnight and holiday coverage. This hybrid model gives 24/7 protection while preserving engineering productivity and avoiding burnout.
Error Budgets & Prioritization
Use error budgets tied to SLIs to make data-driven trade-offs between reliability and features. Teams that use error budgets deliver more predictable releases and prioritize reliability work when it matters most.
✅ Business Impact
Sahi clients see 60–80% reduction in incident toil and up to 3x faster incident remediation. One mid-stage SaaS customer moved from weekly outages to consistent 99.9% uptime after our program.
SRE maturity isn’t an all-or-nothing commitment. Sahi helps you build the practices and automation your team actually needs, scaled to your current stage. We’ll run a 30-minute working session to map reliability to your business outcomes and outline a realistic roadmap. Schedule a Working Session →